

EUInstruct : un corpus d’instructions européen, pour des LLM vraiment multilingues
ChatGPT s'exprime en apparence dans un français irréprochable. Et pourtant, le monde de ChatGPT reste principalement anglophone. Ses capacités se dégradent rapidement dès que l'on sollicite un savoir ou des références culturelles extérieures : les spécialistes d'informatique juridique constatent aujourd'hui que ChatGPT est quasiment inutilisable pour se documenter sur le droit français à moins d'être dirigé en amont.
Ce manque de diversité linguistique est encore plus visible dans le nouvel écosystème alternatif des LLM en open source. Pour devenir un modèle conversationnel comparable à ChatGPT, un modèle de langue doit être entraîné sur un corpus d'instruction, soit une série d'exemples de requêtes et de réponses qui correspondent approximativement aux attentes des utilisateurs. Le corpus d'instruction n'a pas besoin de couvrir tous les sujets potentiellement abordés par le modèle, il doit juste fournir un cas typique de situation de communication avec un assistant conversationnel.
Dans leur grande majorité, les jeux d'instructions ouverts sont en anglais. Alpaca, la base de référence de Stanford, qui a imposé le format standard repris un peu partout (instruction / input / output) est uniquement anglophone.
Le projet EUInstruct vise à réunir l'ensemble des instructions aujourd'hui disponibles dans les principales langues européennes (hors anglais). Il s'appuie sur deux principales sources : des instructions anglophones traduites, et des instructions originales produites directement par des locuteurs natifs.
Alpaca a donné lieu à plusieurs projets de traduction automatique dans les principales langues européennes. Ces jeux d’instructions traduites ne corrigent pas les biais culturels de la source d’origine : par exemple, les livres cités en exemples dans des questions littéraires seront presque exclusivement anglo-saxons. Néanmoins, ils permettent de rapidement créer une interaction conversationnelle dans la langue visée.
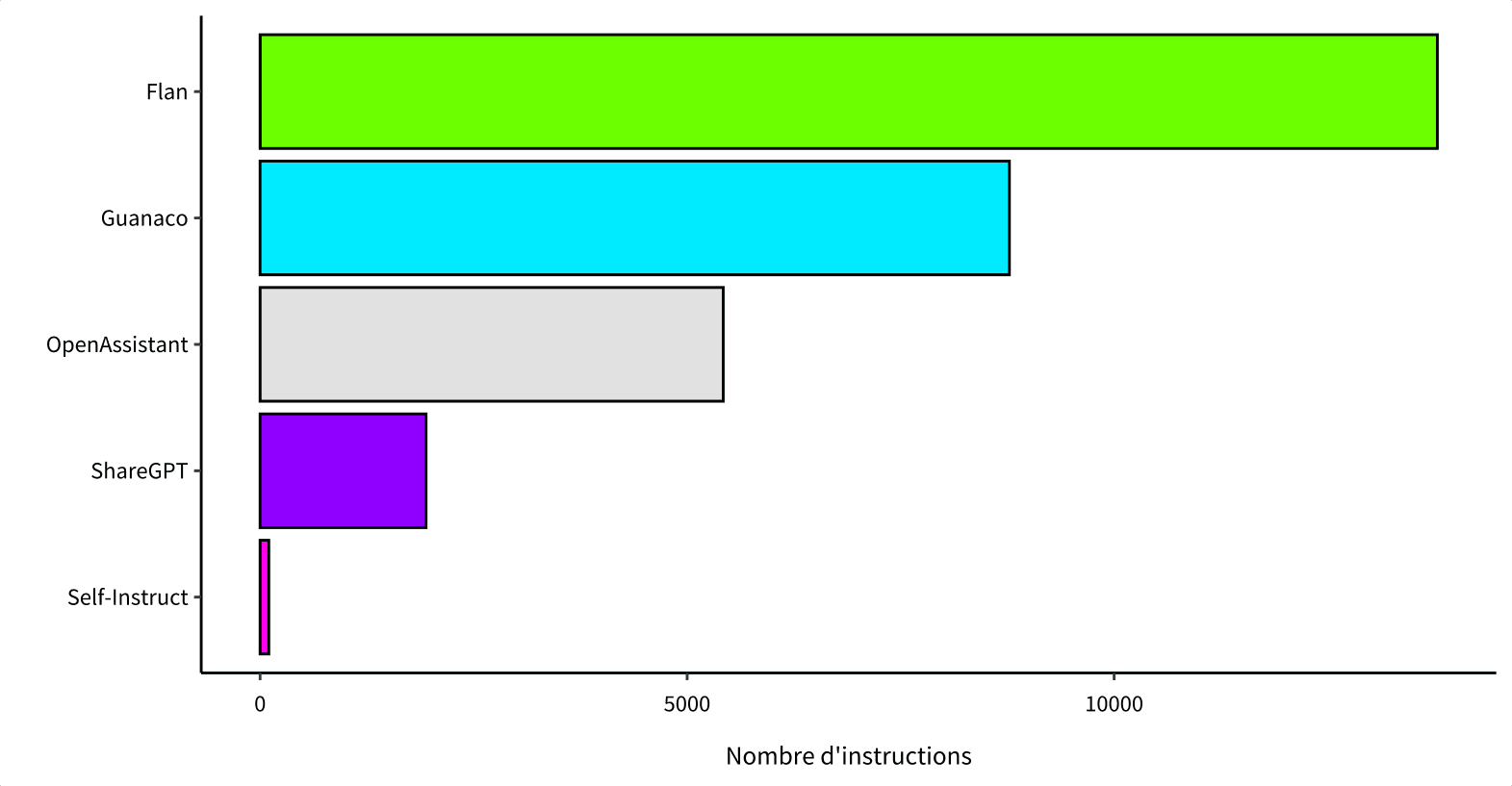
De nouveaux sets, en partie générés par ChatGPT ou d'autres modèles en open source, incorporent un grand nombre de requêtes déposées par des utilisateurs au profils très variés : Guanaco, ShareGPT, OpenAssistant. Le projet OpenAssistant repose ainsi sur le crowdsourcing à grande échelle afin de valider les textes générés par plusieurs LLM ouverts ou utilisables à des finds commerciales.
À partir de techniques de détection de langue, nous avons pu isoler 30 000 instructions non-anglophones. À la différence des instructions traduites d'Alpaca, ces textes sont directement produits par des locuteurs natifs et reflètent leurs préoccupations.
Le projet EUInstruct est structuré par langues plutôt que par provenance. Cela permet de composer rapidement des modèles multilingues correspondant à des usages précis : par exemple un LLM conversationnel suisse pourrait combiner un set francophone, germanophone et italophone.
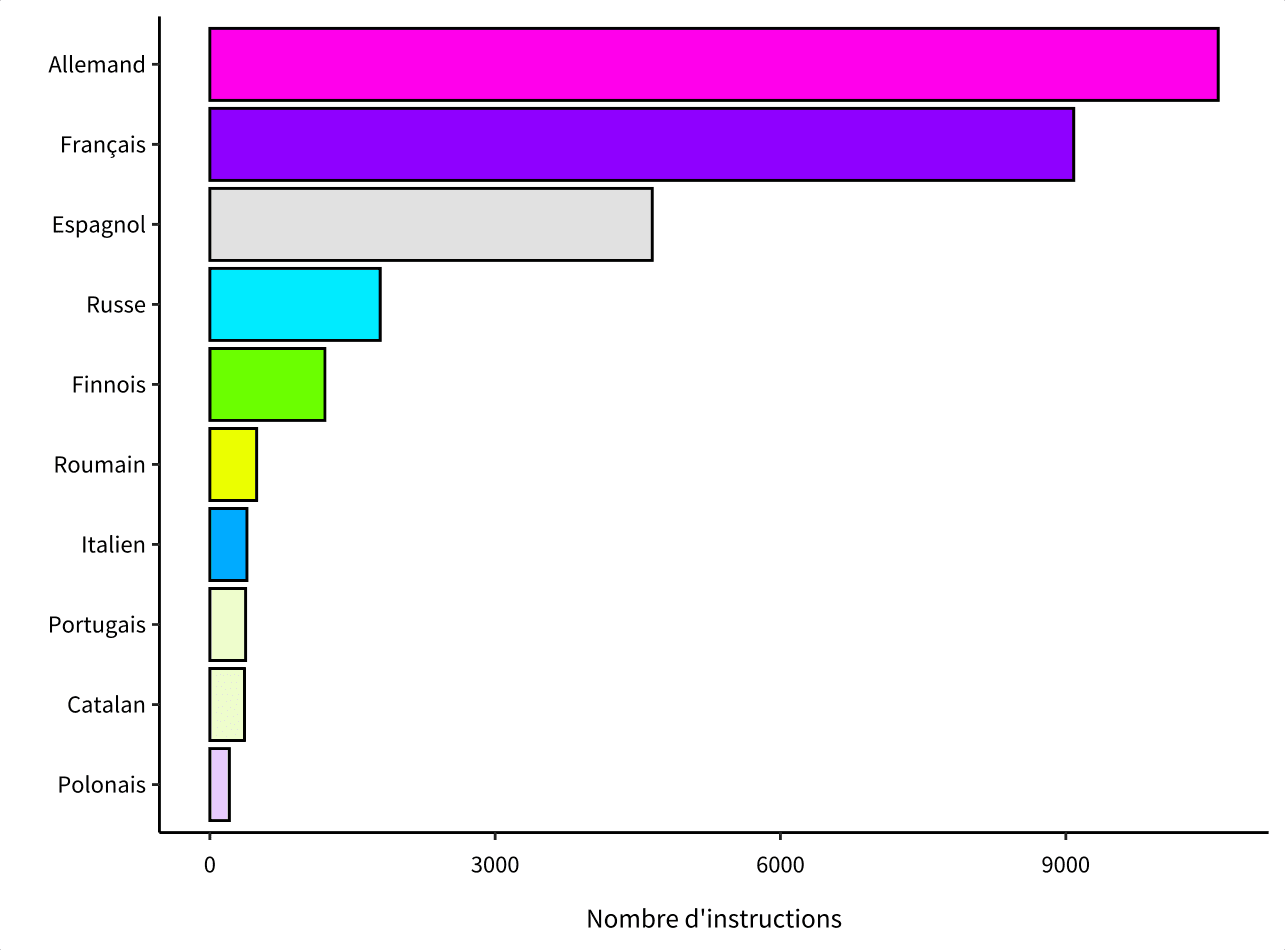
Ce projet met aussi incidemment en lumière le risque d’un accroissement des inégalités linguistiques. Si, dans un futur proche, les grands modèles de langue s’imposent comme des intermédiaires privilégiés dans plein de contextes, les locuteurs de langues moins documentées seront pénalisés et incités à utiliser plutôt une langue véhiculaire.
Il paraît opportun de réfléchir dès aujourd’hui à une stratégie de constitution de corpus et de jeux d’instructions dans des langues mal représentées en ligne. Nos essais sur les variétés historiques du français ou de l’anglais montrent que le fine-tuning sur des corpus d’instruction de taille relativement limitée permet déjà d’améliorer significativement les capacités linguistiques du modèle.